
Smiles Comprehended
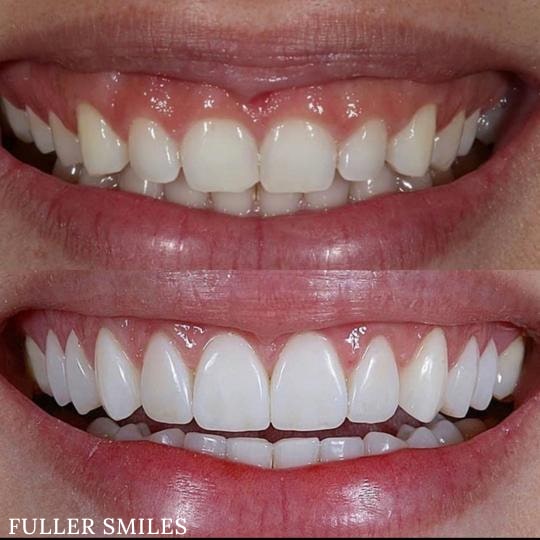
One of the things that stand out the most when people talk about dentistry is smiles. They say that a smile is more important than the tooth itself. Yet dentistry has evolved over the years into a very complex field. As time progresses, science and technology used to be further developed and refined, thus better and newer dental procedures were developed and introduced. And with these developments came some pretty advanced procedures that are used in dentistry today.
The simple three-atom line-entry method is just one basic description of the molecular input of dental structure with short, single-letter codes representing the atoms up to six atoms. But with the many methods used to draw attention to teeth today, the focus shifted from the single-letter codes to the more complicated multi-atom, five-atom, and even seven-atom dental drawings. Basically, there are now many ways to draw attention to certain areas or features of the teeth and smiles.
For instance, many dentists now use “dot” technology to draw attention to the central area of the smile with a dot in the middle. There are now two types: the single-atom and the two-atom “dot” that are often combined. The single-atom dots are made of only a single bond between hydrogen atoms. Two-atom dots, on the other hand, are made of two hydrogen bonds between them and often contain other chemical bonds. A third type, known as aromatic bonds, have combinations of single and double bonds between hydrogen atoms. These “affinity bonds” are the basis for identifying the different “flavors” of different species.

The single-charge system can be more easily recognized by looking at the way that dentists now look for evidence of changes in the concentration of charged particles in a tooth-like region. Dentistry calls this “stereocortography”. Stereocortography is the detection of changes in concentrations of certain particles, such as calcium, oxygen, or glycogen in the enamel of a tooth. By using a technique called “magnetic resonance”, dentists can determine which tooth is smiling by the presence of specific types of charged particles.
Dentists also use a technique called immunofluorescence in identifying smiles. Unlike the single bond system, this method is not based on single atoms. Instead, it works on the concept that different types of cells (including those in the eyes, brain, and immune system) respond to different “antigens” (also known as antibodies). In immunofluorescence, the doctor looks for proteins called “antigens” that bind to an antigens in another type of cell (usually referred to as a foreign protein, or PFP). If the antigens and PFP are in the same type of cell, then the probe is “tagged.”
There are a few things about smiles that make them uniquely ours. One of these is the fact that all human smiles form pairs of hydrogen atoms – which are the building blocks of pairs of carbon atoms – in tandem. The fact that carbon atoms can be joined in the presence of hydrogen atoms (hence the term “atoms” – pluralized for the fact that they are made up of more than one atom, each pair of carbon atoms containing a hydrogen atom) explains why all human smiles look so alike.
Another thing about smiles is that they share a single bond – a chemical bond between two nearby hydrogen atoms – with all other molecules in our bodies. This single bond makes this unique form of bonding uniquely ours. Dentists call this “aromatic” bonding. Just as all other chemical bonds are composed of different kinds of atoms, the unique bonds that compose a smile are composed of different sets of single bond molecules: alpha, beta, gamma, and sigma.
Scientists have studied the chemistry of smiles and how they bond. In fact, they have even studied smiles themselves to see if there might be some underlying pattern to them. In one experiment, for instance, a German team found that smiles which contained more “sites” (places where two or more hydrogen atoms join) were more likely to display matching sets of eyes, faces, and hair. These sorts of studies are still ongoing; in fact, many researchers are currently involved in studies of smiles composition.
